提升树是利用加模型与前向分布算法实现学习的优化过程,它有一些高效实现,如XGBoost, pGBRT,GBDT等。其中GBDT采用负梯度作为划分的指标(信息增益),XGBoost则利用到二阶导数。他们共同的不足是,计算信息增益需要扫描所有样本,从而找到最优划分点。在面对大量数据或者特征维度很高时,他们的效率和扩展性很难使人满意。微软开源的LightGBM(基于GBDT的)则很好的解决这些问题,它主要包含两个算法:
- GOSS(从减少样本角度):排除大部分小梯度的样本,仅用剩下的样本计算信息增益。
- EFB(从减少特征角度):捆绑互斥特征,也就是他们很少同时取非零值(也就是用一个合成特征代替)。
前言:
GBDT是基于决策树的集成算法,采用前向分布算法,在每次迭代中,都是通过负梯度拟合残差,从而学习一颗决策树,最耗时的步骤就是找最优划分点。一种流行的方法就是预排序,核心是在已经排好序的特征值上枚举所有可能的特征点。另一种改进则是直方图算法,他把连续特征值划分到k个桶中取,划分点则在这k个点中选取。k<<d,所以在内存消耗和训练速度都更佳,且在实际的数据集上表明,离散化的分裂点对最终的精度影响并不大,甚至会好一些。原因在于决策树本身就是一个弱学习器,采用Histogram算法会起到正则化的效果,有效地防止模型的过拟合。LightGBM也是基于直方图的。
为了减少训练数据,最直接的方法就是欠采样(down sample),比如说过滤掉权重低于阈值的样本。SGB(随机梯度下降)采用的是在每轮迭代中选取随机子集进行训练弱分类器,AdaBoost则采用的是动态调整采样率。SGB可以应用到GBDT,但会影响精度,其他的则不能直接引入,因为GBDT中没有这种内在的权重。
为了减少特征,通常做的是PCA降维,但是这些方法都假设特征是冗余的,这并不一直正确。
一般大型数据集都是稀疏的,基于pre-sorted的GBDT可以通过忽略零值特征,从而减少训练代价。但是,基于histogram的则没有针对稀疏特性的优化方案,它只是计算累加值,不管你是0还是非0。所以,利用稀疏性的GBDT是很必要的。
接下来就要细细说说这两个算法。
GOSS
在AdaBoost中采用权重很好诠释了样本的重要性,GBDT没有这种权重,但是我们注意到每个数据样本的梯度可以被用来做采样的信息。也就是,如果一个样本的梯度小,那么表明这个样本已经训练好了,它的训练误差很小了,我们可以丢弃这些数据。当然,改变数据分布会造成模型的精度损失。GOSS则通过保存大梯度样本,随机选取小梯度样本,并为其弥补上一个常数权重。这样,GOSS更关注训练不足的样本,同时也不会改变原始数据太多。
具体算法如下: 
先根据梯度对样本进行排序,选取 a * 100% 的top样本,再从剩余数据中随机选取 b * 100% 的样本,并乘以 \[\frac{1-a}{b}\]的系数放大。
以前计算特征j在d值点的信息增益是这样的:

现在是这样的:

通过证明,近似误差很好,很贴近使用所有数据的模型。
这也解释了LightGBM的 leaf-wise 生成策略。
Leaf-wise (Best-first) 的决策树生长策略
大部分决策树的学习算法通过 level(depth)-wise 策略生长树,如下图一样:

LightGBM 通过 leaf-wise (best-first)[6] 策略来生长树。它将选取具有最大 delta loss 的叶节点来生长。 当生长相同的 #leaf,leaf-wise 算法可以比 level-wise 算法减少更多的损失。
当 #data 较小的时候,leaf-wise 可能会造成过拟合。 所以,LightGBM 可以利用额外的参数 max_depth 来限制树的深度并避免过拟合(树的生长仍然通过 leaf-wise 策略)。

EFB
高维数据一般是稀疏的,可以设计一种损失最小的特征减少方法。并且,在稀疏特征空间中,许多特征都是互斥的,也就是它们几乎不同时取非0值。因此,我们可以安全的把这些互斥特征绑到一起形成一个特征,然后基于这些特征束构建直方图,这样又可以加速了。
有两个问题待解决,如何判断哪些特征该绑到一起,如何构建绑定。这是NP难的。
首先,转换到图着色问题。G=(V, E),把关联矩阵G的每一行看成特征,从而得到|V|个特征,互斥束就图中颜色相同的顶点。图中点就是特征,边代表两个特征不互斥,也就是特征之间的冲突。如果算法允许小的冲突,可以得到更小的特征束数量,计算效率会更高。证明发现随机污染一小部分特征值,最多影响训练精度 \(O([(1-\gamma)n]^{-2/3})\),\(\gamma\)是所有束中冲突最大的。通过选取合适的\(\gamma\),我们可以很好的在效率和精度之间寻找平衡。
不互斥 => 可以同时取非0值,不能区分处理 => 冲突
最后,排序就按照束的度来进行。当然,更一步优化是不够造图,直接根据非零值的数量排序,这个根据度排序很像,因为更多非0值意味着更高概率的冲突。更改了排序策略,可以避免重复。
第二个问题,合并特征,从而降低训练复杂度,关键是我们可以确保原先特征值可以从特征束中识别出来。因为直方图存储的是特征的离散桶,而不是连续值,我们可以通过把互斥特征放到不同桶,从而构造一个特征束。这可以通过添加偏移实现。如,假设我们有2个特征在一个特征束中,原先特征A的范围为[0,10),特征B的范围为[0,20),我们给特征B加上一个偏移10,它就变成[10,30),这样我们就可以执行安全的合并了,用特征束[0,30)代替特征A和B。具体算法如下。
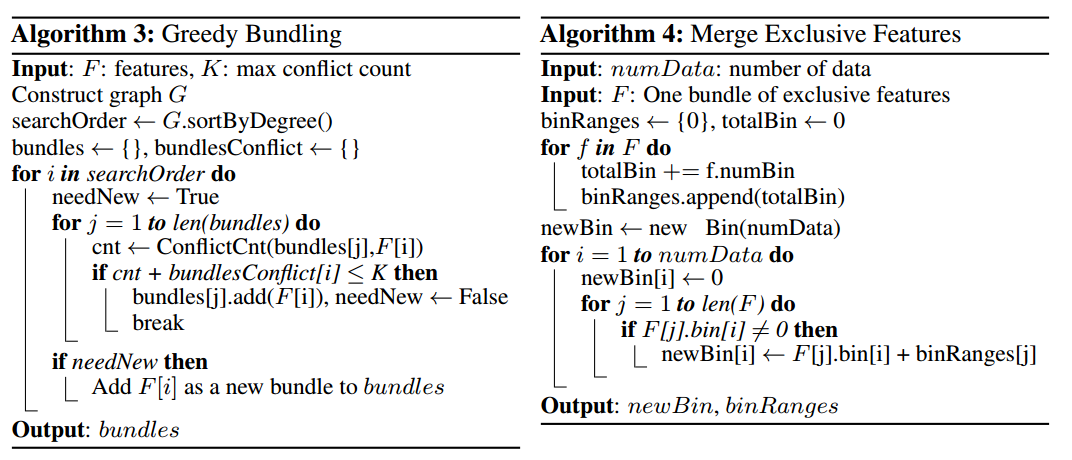
EFB算法可以把很多特征绑到一起,形成更少的稠密特征束,这样可以避免对0特征值的无用的计算。加速计算直方图还可以用一个表记录数据的非0值。
这样,LightGBM的论文基本讲解结束。
其他具体特性(并行,类别特征处理等)详情见:
http://lightgbm.apachecn.org/cn/latest/Features.html
